
MongoDB is a document-oriented NoSQL database, used as data backbone or a polyglot member for many enterprise and internet-targeted systems. It has an extensive querying capability (one of the most thorough in NoSQL realm), and integration is provided by most of popular application development frameworks. There are challenges in terms of flexible scaling, but it’s a great product to work with once you come to terms with some of the nuances (you need patience though).
We’re using MongoDB as an event store in a AWS deployed financial data management application. The application has been optimized for write operations, as we have to maintain structures from data feeds almost throughout the day. There are downstream data consumers, but given defined query patterns, read performance is well within the defined SLA. In this blog, I’ll share some of the key aspects that could help improve write performance of a MongoDB cluster. All of these might not make sense for everyone, but a combination of a few could definitely help. MongoDB version we’re working with is 3.0.
- Sharding – Sharding is a way to scale-out your data layer. Many in-memory and NoSQL data products support sharded clusters on commodity hardware, and MongoDB is one of those. A shard is a single MongoDB instance or a replica-set, that holds a subset of total data in the cluster. Data is divided on basis of a defined shard key, which is used for routing requests to different shards (by mongos router). A production-grade sharded cluster takes some time to setup and tune to what’s desired, but yields good performance benefits once done right. Since data is stored in parts (shards), multiple parts can be simultaneously written to without much contention. Read operations also get a kick if queries contain the shard key (otherwise those can be slower than non-sharded clusters). Thus, choosing the right shard key becomes the most important decision.
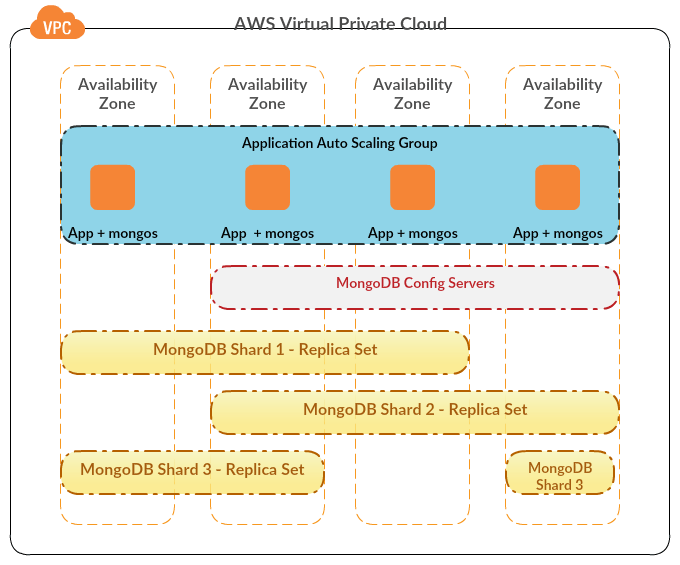
- Storage Engine – Storage engine determines how data will be stored in memory and on disk. There are two main storage engines in MongoDB – WiredTiger and MMAPv1. MMAPv1 was default until version 3.0, and WiredTiger is default in 3.2. Biggest difference between the two is that MMAPv1 has at best collection-level locking for writes, whereas WiredTiger has document level locking (mostly optimistic). Thus, WiredTiger can allow for a more fine-grained concurrency control, and more parallel writes possibly. WiredTiger also comes with data compression on disk, plus has a checkpointing feature to maintain consistency (in addition to default Journaling). If you’re using version 3.0, MMAPv1 could still be good enough given that it’s a tried and tested component and WiredTiger was still fairly new at that point.
- Write Concern – Write concern allows one to define the degree of acknowledgement indicating success of a write operation. If a system can easily recover write losses without observable impact to users, then it’s possible to do away with acknowledgements altogether, so as to make the write round-trip as fast as possible (Not allowed if Journaling is ON). By default, acknowledgement is required from a standalone instance or primary of a replica set. If one wants strong consistency from a replica set, write concern can be configured to be more than 1 or “majority” to make sure writes have propagated to some replica nodes as well (though it’s done at cost of degraded write performance).
- Journaling – Journaling is basically write-ahead logging on disk to provide consistency and durability. Any chosen storage engine by default writes more often to the journal than to the data disk. One can also configure Write Concern with “j” option, which indicates that operation will be acknowledged after it’s written to the journal. That allows for more consistency, but overall performance can take a hit (duration between Journal commits is decreased automatically to compensate though). From a performance perspective, there’re a couple of things one can do with respect to Journaling – 1. Keep journal on a different volume than the data volume to reduce I/O contention, and/or 2. Reduce interval between journal commits (please test this thoroughly, as too less a value can eventually decrease overall write capacity).
- Bulk Writes – One can write multiple documents in a collection through a single bulk-write operation. Combined with WiredTiger storage engine, this can be a great way to make overall writes faster if it’s possible to chunk multiple writes together. Though if you’ve a e-commerce system, and you need to handle write operations per user transaction, it might not be a great option. Bulk writes can be ordered (serial and fail-fast) or unordered (parallel isolated writes), and the choice depends on specific requirements of a system.
There’re other general and non-intrusive ways to improve overall performance of a MongoDB cluster, like increase memory (to reduce read page faults), use SSD for data volume, or increase disk IOPS (should be employed if cost and infra limits permit). What we’ve covered above are specific MongoDB provided features, which can be played around with, provided there’s appetite.
Hope this was a wee bit helpful.
