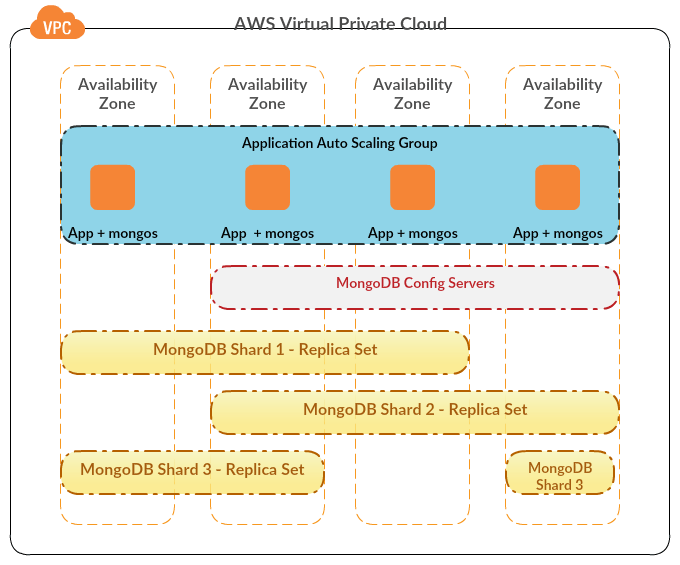
If you want a true copy of your MongoDB cluster data in case of data corruption, accidental deletion or disaster recovery, you’ll want to back it up reliably. Automated backup of a MongoDB cluster (with multiple shards) gets a bit complex, because any replica-set stores only one shard at a time, and relevant product utilities dump/export data only from one node at a time. Thus we need to build a custom mechanism to backup all shards simultaneously.
If your MongoDB cluster is setup on AWS, best possible place to store regular backups is S3. And even if the cluster is on-premises, S3 is still a wonderful option (Similar options exist for Azure, Rackspace etc.). Few things to note:
- You’ll need appropriate permissions to relevant S3 bucket, to store your regular backups.
- If your MongoDB cluster is on AWS EC2 nodes, it’ll most probably assume a IAM role to interact with other AWS services. In that case, S3 bucket permissions should be granted to the role.
- If your MongoDB cluster is not on AWS, S3 bucket permissions should be granted to a specific IAM user (better to create a specific backup user). You should have the access credentials for that user (AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY).
- Backup of each MongoDB shard should be taken from one of the secondary nodes of related replica-set. This is to avoid impacting the primary node during backup.
- To avoid taking duplicate backups on multiple secondary nodes of a replica-set, backup script should run on primary node of that replica-set and connect to one of the secondaries.
- Each replica-set’s backup node (one of the secondaries) should be locked against any writes during the operation, to avoid reading in-flight writes. It should be unlocked after the backup is complete.
- You could create a cron job to automate periodic execution of the backup script. If you’re using DevOps to provision your cluster, cron job setup can be done there. We’re using this approach (AWS Cloudformation), to avoid any manual setup.
- If you’ve a self-healing cluster (like AWS Autoscaling in our case), backup script should be configured to run on all nodes in the cluster. In such a case, script should be intelligent enough to identify the shard and type of node (primary/secondary).
Now the intelligent script:
#!/usr/bin/env bash
export AWS_DEFAULT_REGION=us-east-1
## Provide AWS access credentials if not running on EC2,
## and relevant IAM role is not assumed
# export AWS_ACCESS_KEY_ID=xxx
# export AWS_SECRET_ACCESS_KEY=yyy
## AWS S3 bucket name for backups
bucket=mybucket
## Create this folder beforehand on all cluster nodes
cd /backup
## Check if the cluster node is a replica-set primary
mongo --eval "printjson(db.isMaster())" > ismaster.txt
ismaster=`cat ismaster.txt | grep ismaster | awk -F'[:]' '{print $2}' |
cut -d "," -f-1 | sed 's/ //g'`
echo "master = $ismaster"
if [ "$ismaster" == "true" ]; then
## It's a replica-set primary, get the stored shard's name
shardname=`cat ismaster.txt | grep "setName" | awk -F'[:]'
'{print $2}' | grep shard | cut -d"-" -f-1
| sed 's/\"//g' | sed 's/ //g'`
echo "Shard is $shardname"
## Create a time-stamped backup directory on current primary node
NOW=$(TZ=":US/Eastern" date +"%m%d%Y_%H%M")
snapshotdir=$shardname-$NOW
echo "Creating folder $snapshotdir"
mkdir $snapshotdir
## Get the IP address of this primary node
primary=`cat ismaster.txt | grep primary | awk -F'[:]' '{print $2}'
| sed 's/\"//g' | sed 's/ //g'`
echo "Primary node is $primary"
## Connect to one of the secondaries to take the backup
cat ismaster.txt
| sed -n '/hosts/{:start /]/!{N;b start};/:27017/p}'
| grep :27017 | awk '{print $1}' | cut -d "," -f-1
| sed 's/\"//g'
| (while read hostipport; do
hostip=`echo $hostipport | cut -d":" -f-1`
echo "Current node is $hostip"
## Check if IP address belongs to a secondary node
if [ "$hostip" != "$primary" ]; then
## Lock the secondary node against any writes
echo "Locking the secondary $hostip"
mongo --host $hostip --port 27017 --eval
"printjson(db.fsyncLock())"
## Take the backup from secondary node,
## into the above created directory
echo "Taking backup using mongodump connecting
to $hostip"
mongodump --host $hostip --port 27017 --out
$snapshotdir
## Unlock the secondary node, so that it could
## resume replicating data from primary
echo "Unlocking the secondary $hostip"
mongo --host $hostip --port 27017 --eval
"printjson(db.fsyncUnlock())"
## Sync/copy the backup to S3 bucket,
## in shard specific folder
echo "Syncing snapshot data to S3"
aws s3 sync $snapshotdir
s3://$bucket/mongo-backup/$shardname/$NOW/
## Remove the backup from current node,
## as it's not required now
echo "Removing snapshot dir and temp files"
rm -rf $snapshotdir
rm ismaster.txt
## Break from here, so that backup is taken only
## from one secondary at a time
break
fi
done)
else
## It's not a primary node, exit
echo "This node is not a primary, exiting the backup process"
rm ismaster.txt
fi
echo "Backup script execution is complete"
It’s not perfect, but it works for our multi-shard/replica-set MongoDB cluster. We found this less complex than taking AWS EBS snapshots and re-attaching relevant snapshot volumes in a self-healing cluster. We’d explored few other options, so just listing those here:
- An oplog based backup – https://github.com/journeyapps/mongo-oplog-backup
- https://github.com/micahwedemeyer/automongobackup
Hope you found it a good read.