
Amazon Simple Queue Service (SQS) is a HA cloud messaging service, that can be used to decouple parts of a single system, or integrate multiple disparate systems. A SQS queue acts as buffer between a message producer and a consumer, when former’s message generation rate is more than latter’s processing throughput. It also provides durable point-to-point messaging, such that messages are stored in a fail-safe queue, and can be processed once a consumer application comes up after scheduled maintenance or unexpected downtime. For publish-subscribe design pattern, Amazon (AWS) provides another cloud service called Simple Notification Service (SNS).

Above diagram shows a subset of possible producer-consumer scenarios that can utilize SQS.
For developers who use JMS to connect to messaging providers/brokers like ActiveMQ, Websphere MQ, JBoss Messaging etc., they can use Amazon SQS Java Messaging Library to work with SQS. One can use it along with AWS SDK to write JMS 1.1 compliant applications. But for real-world applications, writing directly with AWS provided library can be cumbersome. That’s where Spring Cloud AWS comes to the rescue. In this post, I’ll show how one can use Spring Cloud with Spring Boot to write a SQS message producer and a consumer. Before that, a few important points to note when working with SQS:
- Maximum payload of a SQS message can be 256 KB. For applications that have need to send more data in a single packet, could use SQS Extended Client Library which utilizes AWS S3 as the message store (with a reference being sent in actual SQS message). Other option is to compress the message before sending over SQS.
- Messages can be sent synchronously, but received either synchronously or asynchronously (Using AmazonSQSAsyncClient). If required, one can send messages in a separate child thread so as not to block the main thread for SQS IO operation.
- Messages can be sent or received in batch to increase throughput (10 messages at max in a batch). Please note that maximum payload size limit for a batch message is also 256 KB, so it can only be used for lighter payloads.
- There can be multiple producer and consumer threads interacting with the same queue, just like any other messaging provider/broker. Multiple consumer threads provide load balancing for message processing.
- Consumers can poll for messages using long polling and standard polling. It’s recommended to use long polling to avoid too many empty responses (one can configure timeout).
- Each message producer or consumer needs AWS credentials to work with SQS. AWS provides different implementations of AWSCredentialsProvider for the same. DefaultAWSCredentialsProviderChain is used by default, if no provider is configured specifically.
Now, how to use Spring Cloud with SQS. First of all, below dependencies should be provided in Maven project’s pom.xml or Gradle’s build file. AWS SDK and other Spring dependencies would be automatically added to the classpath (unless already specified explicitly).
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-aws-autoconfigure</artifactId>
<version>latest.version</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-aws-messaging</artifactId>
<version>latest.version</version>
</dependency>
From a configuration perspective, we first need to wire the appropriate AWS SQS client. Assuming asynchronous interaction with SQS, we will configure a AmazonSQSAsyncClient. There’re a couple of things to note. One, if you’re behind a proxy, you’ll need to specify proxy host and port using ClientConfiguration. Second, DefaultAWSCredentialsProviderChain will look for AWS access key, secret access key and default region in this order – environment variables, system variables, properties file and instance profile (only in EC2). We’ve just overridden the default region below (which is also us-east-1 though).
@Lazy
@Bean(name = "amazonSQS", destroyMethod = "shutdown")
public AmazonSQSAsync amazonSQSClient() {
AmazonSQSAsyncClient awsSQSAsyncClient;
if (useProxy.equalsIgnoreCase("Y")) {
ClientConfiguration clientConfig = new ClientConfiguration();
clientConfig.setProxyHost("proxy.xyz.com");
clientConfig.setProxyPort(8085);
awsSQSAsyncClient = new AmazonSQSAsyncClient(new DefaultAWSCredentialsProviderChain(), clientConfig);
} else {
awsSQSAsyncClient = new AmazonSQSAsyncClient(new DefaultAWSCredentialsProviderChain());
}
awsSQSAsyncClient.setRegion(Region.getRegion(Regions.fromName("us-east-1")));
return awsSQSAsyncClient;
}
Next we look at configuring a QueueMessagingTemplate, which will be used to send messages to a SQS queue.
@Configuration
public class ProducerAWSSQSConfig {
...
@Bean
public QueueMessagingTemplate queueMessagingTemplate() {
return new QueueMessagingTemplate(amazonSQSClient());
}
@Lazy
@Bean(name = "amazonSQS", destroyMethod = "shutdown")
public AmazonSQSAsync amazonSQSClient() {
...
}
@Component
public class MessageProducer {
private QueueMessagingTemplate sqsMsgTemplate;
...
public void sendMessage(String payload) {
...
this.sqsMsgTemplate.convertAndSend("randomQName", payload);
...
}
}
We’re sending a String message, which will be converted using a StringMessageConverter internally. One can also send a complete data object as JSON, if Jackson library is available on classpath (using MappingJackson2MessageConverter).
Finally, we look at configuring a SimpleMessageListenerContainer and QueueMessageHandler, which will be used to create a message listener for SQS queue. Please note that internally Spring Cloud creates a SynchonousQueue based thread pool to listen to different queues and to process received messages using corresponding handlers. Number of core threads for thread pool are 2 * number of queues (or configured listeners), and property “maxNumMsgs” determines the maximum number of threads. Property “waitTimeout” determines the timeout period for long polling (default with Spring Cloud).
public class ConsumerAWSSQSConfig {
...
@Bean
public SimpleMessageListenerContainer simpleMessageListenerContainer() {
SimpleMessageListenerContainer msgListenerContainer = simpleMessageListenerContainerFactory().createSimpleMessageListenerContainer();
msgListenerContainer.setMessageHandler(queueMessageHandler());
return msgListenerContainer;
}
@Bean
public SimpleMessageListenerContainerFactory simpleMessageListenerContainerFactory() {
SimpleMessageListenerContainerFactory msgListenerContainerFactory = new SimpleMessageListenerContainerFactory();
msgListenerContainerFactory.setAmazonSqs(amazonSQSClient());
msgListenerContainerFactory.setDeleteMessageOnException(false);
msgListenerContainerFactory.setMaxNumberOfMessages(maxNumMsgs);
msgListenerContainerFactory.setWaitTimeOut(waitTimeout);
return msgListenerContainerFactory;
}
@Bean
public QueueMessageHandler queueMessageHandler() {
QueueMessageHandlerFactory queueMsgHandlerFactory = new QueueMessageHandlerFactory();
queueMsgHandlerFactory.setAmazonSqs(amazonSQSClient());
QueueMessageHandler queueMessageHandler = queueMsgHandlerFactory.createQueueMessageHandler();
return queueMessageHandler;
}
@Lazy
@Bean(name = "amazonSQS", destroyMethod = "shutdown")
public AmazonSQSAsync amazonSQSClient() {
...
}
@Component
public class MessageConsumer {
...
@MessageMapping("randomQName")
public void onRandomQMessage(String payload) {
doSomething(payload);
}
}
One can also send custom message attributes (headers) with a SQS message, so as to provide contextual information to the consumer. In addition, there’re important concepts of visibility timeout and delay queues, which should be explored before getting your hands dirty with SQS.
Hope you have fun with Spring Cloud and AWS SQS.

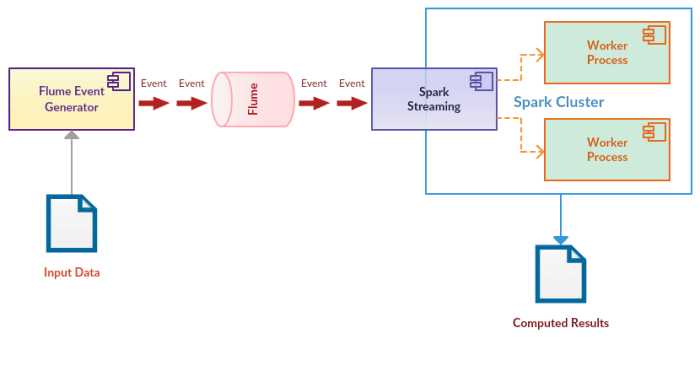 It’s a hypothetical problem, hence you’ll see events being generated from a finite dataset (CSV file of consumer complaint records – many columns removed to keep it simple). Our sample data looks like this:
It’s a hypothetical problem, hence you’ll see events being generated from a finite dataset (CSV file of consumer complaint records – many columns removed to keep it simple). Our sample data looks like this: