Apache Spark has more than taken off by now. It’s being used to solve myriad types of data analysis problems, whether it’s a recommendation system for a modern retail store, or a business intelligence platform for a conservative financial asset manager, and many. Apart from its features and performance to reckon with, a big part of Spark’s success was its support for Python, which led to its widespread adoption. And now they’ve added a R package SparkR, which has been a attention grabber for all those R enamored data scientists out there. No doubt it has taken a fair share of limelight from Hadoop Mapreduce.
Apart from the core Spark engine, there’re four add-on modules that make this framework a powerhouse to reckon with:
- Spark Streaming – to process real-time data streams
- Spark SQL and Dataframes – to support relational data analysis, and data structures common to R and Python Pandas.
- Spark MLib – to create machine learning applications
- Spark GraphX – to solve graph functional problems, like in hierarchies, networks etc.
In this post, we’ll look at a simple data problem, which needs some computation over a continuous stream of US consumer complaints data (Source: Data.gov). We’ll be using Spark Streaming (Java API) with Apache Flume (a data collector and aggregator) to exemplify real-time data analysis. Flume will be used as a generator of real-time data events (for sake of simplicity, we’re using a finite dataset). Whereas a standalone Spark Streaming program will consume events as they are generated, maintain a rolling count of consumer complaints by type and US state, and store results to a file at a frequency.
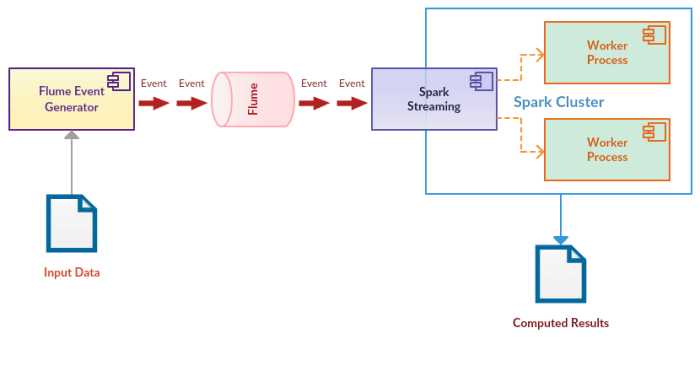 It’s a hypothetical problem, hence you’ll see events being generated from a finite dataset (CSV file of consumer complaint records – many columns removed to keep it simple). Our sample data looks like this:
It’s a hypothetical problem, hence you’ll see events being generated from a finite dataset (CSV file of consumer complaint records – many columns removed to keep it simple). Our sample data looks like this:
"Debt collection","Credit card","MA"
"Bank account or service","Checking account","TN"
"Consumer loan","Vehicle loan","FL"
"Bank account or service","Savings account","PA"
"Debt collection","","GA"
"Debt collection","Credit card","FL"
"Debt collection","Medical","DE"
"Credit reporting","","TX"
"Mortgage","Other mortgage","CA"
First we see a basic Flume event generator (with Avro source). It needs a running Flume agent (directions mentioned below). Full source for event generator is available at Flume Client.
// Initialize connection to Flume agent, and the event source file
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
try {
InputStream inStream = this.getClass().getClassLoader()
.getResourceAsStream("cons_comp_data.csv");
Reader in = new InputStreamReader(inStream);
csvRecords = CSVFormat.DEFAULT.
withSkipHeaderRecord(true).parse(in);
}
.......
.......
}
// Send records from source file as events to flume agent
public void sendDataToFlume() {
CSVRecord csvRecord = null;
Iterator csvRecordItr = csvRecords.iterator();
while (csvRecordItr.hasNext()) {
try {
csvRecord = csvRecordItr.next();
String eventStr = csvRecord.toString();
System.out.println(eventStr);
Event event = EventBuilder.withBody(eventStr,
Charset.forName("UTF-8"));
client.append(event);
}
.......
.......
}
}
Now we take a look at the Spark Streaming program, which processes each event to maintain a rolling count by complaint type and state. At the start, we create a JavaStreamingContext, which is the entry point to a Spark Streaming program, and create a input stream of events using Spark-Flume integration.
SparkConf sparkConf = new SparkConf().setAppName("ConsCompEventStream");
// Create the context and set the checkpoint directory
JavaStreamingContext context = new JavaStreamingContext(sparkConf,
new Duration(2000));
context.checkpoint(checkpointDir);
// Create the input stream from flume sink
JavaReceiverInputDStream flumeStream = FlumeUtils.createStream(context, h ost, port);
We are setting a checkpoint folder in JavaStreamingContext, which is used to create Fault tolerant Spark Streaming applications. It allows the application to recover from failures. Please read more at Spark Checkpointing.
Rest of the program processes each Flume event in logical steps:
- Use map() function to convert incoming stream of events to a JavaDStream. This allows us to convert each Flume event into a processable format.
- Use mapToPair() function to convert each processable event to a JavaPairDStream of complaint type and US state.
- Use updateStateByKey() function to maintain a rolling count by complaint type and US state.
- Use foreachRDD() function to store the rolling count to a file periodically.
// Transform each flume avro event to a processable format
JavaDStream transformedEvents = flumeStream
.map(new Function<SparkFlumeEvent, String>() {
.........
};
// Map key-value pairs by product and state to count of 1
JavaPairDStream<Tuple2<String, String>, Integer> countOnes = transformedE vents
.mapToPair(new PairFunction<String, Tuple2<String, String>, Integer>() {
.........
};
// Maintain a updated list of counts per product and state
JavaPairDStream<Tuple2<String, String>, List> updatedCounts = countOnes
.updateStateByKey(new Function2<List, Optional<List>, Optio nal<List>>() {
.........
};
// Store the updated list of counts in a text file per product and state
updatedCounts.foreachRDD(new Function<JavaPairRDD<Tuple2<String, String>, List>, Void>() {
.........
};
Full source is available at Spark Flume Stream. It also includes complete information on how to configure and run the Flume agent, as well as how to run this program using a local Spark cluster. The implementation is in Java 1.7, hence the use of anonymous inner classes. It can look a lot concise and prettier if converted to use lambdas with Java 8. I won’t mind a merge request for the same ;-).
