
The global sports market is huge, comprising of players, teams, leagues, fan clubs, sponsors etc., and all of these entities interact in myriad ways generating enormous amount of data. Some of that data is used internally to help make better decisions, and there are number of use cases within the Media industry that utilize the same data to create better products and attract/retain viewers.
Few ways how the Sports and Media industries have started utilizing big data are:
- Analyze on-field conditions and events (passes, player positions etc.) that lead to soccer goals, football touchdowns or baseball home runs etc.
- Assess the win-loss percentage with different combinations of players in different on-field positions.
- Track a sportsperson’s or team’s performance graph over the years/seasons
- Analyze real-time viewership events and social media streams to provide targeted content, and more..
European Soccer Leagues Data
We all have a favorite sport, and mine is Soccer for its global appeal, amazing combination of skills & strategy, and the extreme fans that add extra element to the game.
In this article, we’ll see how one could use Databricks to create an end-to-end data pipeline with European Soccer games data – including facets from Data Engineering, Data Analysis and Machine Learning, to help answer business questions. We’ll utilize a dataset from Kaggle, that provides a granular view of 9,074 games, from the biggest 5 European soccer leagues: England, Spain, Germany, Italy and France, from 2011 to 2016 season.
Primary dataset is specific events from the games in chronological order, including key information like:
- id_odsp – unique identifier of game
- time – minute of the game
- event_type – primary event
- event_team – team that produced the event
- player – name of the player involved in main event
- shot_place – placement of the shot, 13 possible placement locations
- shot_outcome – 4 possible outcomes
- location – location on the pitch where the event happened, 19 possible locations
- is_goal – binary variable if the shot resulted in a goal (own goals included)
- And more..
Second smaller dataset includes high-level information and advanced stats with one record per game. Key attributes are “League”, “Season”, “Country”, “Home Team”, “Away Team” and various market odds.
Data Engineering
We start out by creating a ETL notebook, where the two CSV datasets are transformed and joined into a single parquet data layer, which enables us to utilize DBIO caching feature for high-performance big data queries.
Extraction
First task is to create a Dataframe schema for the larger game events dataset, so the read operation doesn’t spend time inferring it from the data. Once extracted, we’ll replace “null” values for interesting fields with data-type specific constants.

This is what the raw data (with some nulls replaced) looks like:
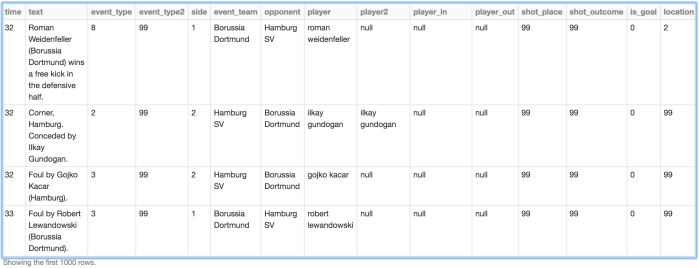
We also read the second dataset into a Dataframe, as it includes country name which we’ll use later during analysis.
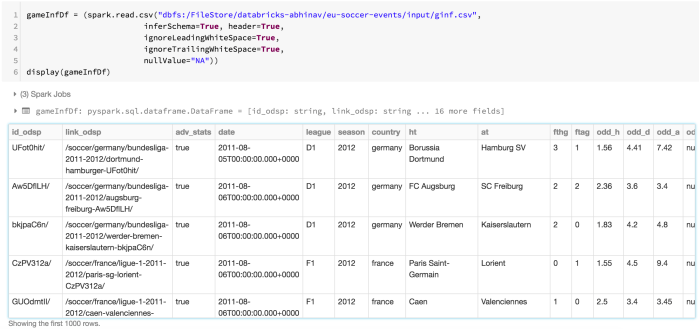
Transformation
Next step is to transform and join the dataframes into one. Many fields of interest in the game events dataframe have numeric IDs, so we define a generic UDF that could use look-up tables for mapping IDs to descriptions.

The mapped descriptions are stored in new columns in the dataframe. So once the two dataframes are joined, we’ll filter out the original numeric columns to keep it as sparse as possible. We’ll also use QuantileDiscretizer to add a categorical “time_bin” column based on “time” field.

Loading
Once the data is in desired shape, we’ll load it as parquet into a Spark/Databricks table that would reside in a domain specific database. The database and table will be registered with internal Databricks metastore, and the data will be stored in DBFS. We’ll partition the parquet data by “country_code” during write.

Data Analysis
Now that the data shape and format is all set, it’s time to dig in and, try and find answers to a few business questions. We’ll use plain-old super-strong SQL (Spark SQL) for that purpose, and create a second notebook from the perspective of data analysts.
For example, if one wants to see distribution of goals by shot place, then it could look like this simple query and resulting pie-chart (or alternatively viewable as a data-grid):

Or if the requirement is to see distribution of goals by countries/leagues, it could look like this map visualization (which needs ISO country codes, or US state codes as a column):

Once we observe that Spanish league has had most goals over the term of this data, we could find top 3 goals locations per shot place from the games in Spain, by writing a more involved query using Window functions in Spark SQL. It would be a stepwise nested query:
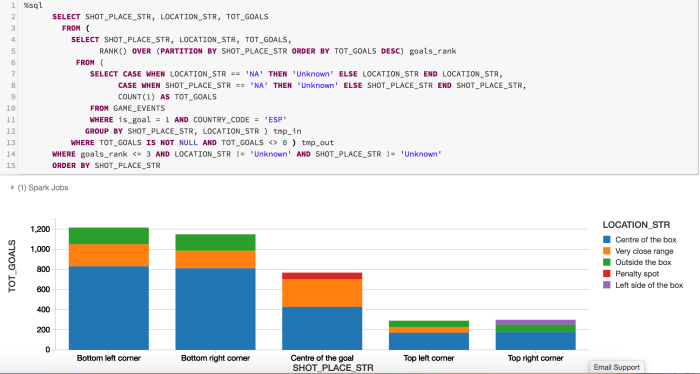
We could do time-based analysis as well, e.g. by observing total number of goals over the course of a game (0-90+ minutes), across all games in the five leagues. We could use the “time_bin” column created as part of transformation process earlier, rather than a continuous variable like “time”:

Machine Learning
As we saw, doing descriptive analysis on big data (like above) has been made super easy with Spark SQL and Databricks. But what if you’re a Data Scientist who’s looking at the same data to find combinations of on-field playing conditions that lead to “goals”?
We’ll now create a third notebook from that perspective, and see how one could fit a GBT classifier Spark ML model on the game events training dataset. In this case, our binary classification label will be field “is_goal”, and we’ll use a mix of categorical features like “event_type_str”, “event_team”, “shot_place_str”, “location_str”, “assist_method_str”, “situation_str” and “country_code”.

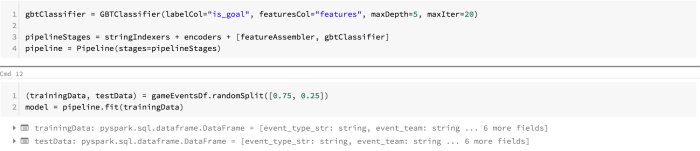
Then the following three-step process is required to convert our categorical feature columns to a single binary vector:
- Convert string features to indices using StringIndexer
- Transform feature indices to binary vectors using OneHotEncoder
- Assemble different binary vector columns into a single vector using VectorAssembler

Finally we’ll create a Spark ML Pipeline using the above transformers and the GBT classifier. We’ll divide the game events data into training and test datasets, and fit the pipeline to the former.
Now we can validate our classification model by running inference on test dataset. We could compare the predicted label with actual label one by one, but that could be a painful process for lots of test data. For scalable model evaluation in this case, we can use BinaryClassificationEvaluator with Area under ROC metric. One could also use the Precision-Recall Curve as evaluation metric. If it was a multi-classification problem, we could’ve used the MulticlassClassificationEvaluator.
Conclusion
Above end-to-end data pipeline showcases how different sets of users i.e. Data Engineers, Data Analysts and Data Scientists could work together to find hidden value in big data from any sports.
But this is just the first step. A Sports or Media organization could do more by running model-based inference on real-time streaming data processed using Structured Streaming, in order to provide targeted content to its users. And then there are many other ways to combine different Spark/Databricks technologies, to solve different big data problems in Sport and Media industries.
Try Databricks on AWS or Azure Databricks today.

Hi, I’m trying this in apache spark Jupiter and I’m getting and error in this line:
gameInfDf = gameInfDf.withColumn(“country_code”, mapKeyToVal(countryCodeMap)(“country”))
NameError: name ‘countryCodeMap’ is not defined
do you know how to solve this?
LikeLike