Apache Lucene is a high performance, cross-platform search engine library, which has gained immense support in enterprises looking to build firm-wide, customer-facing search platforms. And it does owe good share of its popularity to Apache Solr and Elasticsearch, that are matured search products built on top of Lucene. We chose Elasticsearch 2.3.3 (5.0 is the current version at time of writing), to build our multi-entity search platform for a financial services firm.
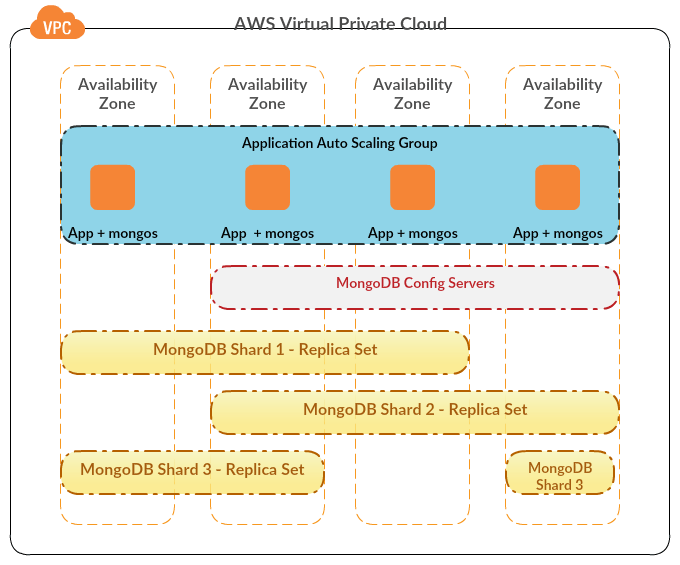
All our applications and data platforms are housed in AWS VPCs. We decided to implement our own cluster on EC2 rather than using AWS Elasticsearch, with main reasons being: AWS Elasticsearch doesn’t provide data encryption using AWS KMS yet (at least at time of writing this); AWS has been generally behind on adding latest Elasticsearch versions; and we wanted full freedom in maintaining our own cluster with choice of security groups, plugins, monitoring etc. Without going into details of infrastructure, I’ll just mention the major plugins we are using:
- EC2-Discovery for unicast discovery (AWS doesn’t support multicast out of box)
- Kopf for web-based administration
- Head for web-based administration
- SQL for data analysis
- Read-only to control maintenance actions (alternative to using Nginx as proxy)

Our indexing and query services have been implemented in Java (using Spring Boot), and we use Elasticsearch’s Java API (Transport Client) to connect to the cluster. We don’t use Spring Data Elasticsearch, as it also lags behind in version upgrades mostly. Now, moving to what we want to focus on in this blog: how to implement a search service for data stored in Elasticsearch.
First and most important component that impacts data indexing and search in Elasticsearch is an Analyzer. Analysis is the process of converting text, like a product description, or a person name into tokens or terms which are added to the inverted index for searching. Analysis is performed by the analyzer which can be either a built-in or custom. There’re three sub-parts to an analyzer, and they process all incoming text in this order:
- Character Filter – Used to preprocess text before indexing/searching, like stripping HTML markup
- Tokenizer – Main component which produces tokens from incoming text
- Token Filter – Can modify, delete or add tokens to stream of tokens from tokenizer
For our product and person search services (90% of our search functionality), we created custom edgeNGram based token filters, and analyzers using those token filters. A edgeNGram token filter is similar to a nGram token filter, except that it only keeps nGrams which start at the beginning of tokens produced by a tokenizer. The analysis settings for such an index look like:
{
"settings": {
"index": {
...
},
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edgeNGram",
"min_gram": "1",
"max_gram": "10"
},
"autocomplete_phrase_filter": {
"type": "edgeNGram",
"min_gram": "1",
"max_gram": "20"
}
},
"analyzer": {
"keyword_analyzer": {
"type": "custom",
"filter": [
"asciifolding","lowercase"
],
"tokenizer": "keyword"
},
"autocomplete_analyzer": {
"type": "custom",
"filter": [
"standard","lowercase","stop","autocomplete_filter"
],
"tokenizer": "standard"
},
"autocomplete_phrase_analyzer": {
"filter": [
"standard","lowercase","autocomplete_phrase_filter"
],
"type": "custom",
"tokenizer": "keyword"
}
}
}
}
}
Now we apply these analyzers to field mappings in the index. In a elaborate search platform, where one needs ability to search a field in different ways, it’s fruitful to store multiple versions of such a field, often using different analyzers during indexing and searching. That way, one could use more relevant version for a given scenario. For e.g.:
{
"settings": {
"index": {
...
},
"analysis": {
...
}
},
"mappings": {
"product": {
"dynamic": "strict",
"_all": {
"enabled": false
},
"properties": {
...
...
"productTypeCode": {
"type": "string",
"norms": {
"enabled": false
},
"analyzer": "keyword_analyzer"
},
"productName": {
"type": "string",
"term_vector": "with_positions_offsets",
"analyzer": "english",
"fields": {
"autocomplete_exact": {
"type": "string",
"norms": {
"enabled": false
},
"analyzer": "keyword_analyzer"
},
"autocomplete_phrase": {
"type": "string",
"norms": {
"enabled": false
},
"analyzer": "autocomplete_phrase_analyzer",
"search_analyzer": "keyword_analyzer"
},
"autocomplete_startswith": {
"type": "string",
"norms": {
"enabled": false
},
"analyzer": "autocomplete_analyzer",
"search_analyzer": "standard"
},
"autocomplete_token": {
"type": "string",
"norms": {
"enabled": false
},
"index_options": "docs",
"analyzer": "standard"
},
"raw": {
"type": "string",
"index": "not_analyzed"
}
}
}
...
...
}
}
}
}
What’s worth noting above is how custom analyzers have been used along with built-in analyzers to map different versions of productName (and other fields like that). This is how different versions could be used during searching:
- productName.autocomplete_exact – to match stored documents that are exactly equal to full queried text (case-insensitive) – Query against “intel corp” will match “Intel Corp“, and not “Intel Corporation“.
- productName.autocomplete_phrase – to match stored documents that start with full queried text (case-insensitive) – Query against “intel corp” will match both “Intel Corp” and “Intel Corporation“.
- productName.autocomplete_token – to match stored documents that have exact tokens as full exact tokens in queried text (case insensitive) – Query against “intel corp” will match not just “intel” products, but also “Microsoft Corp” or any other product with “corp“, but won’t match “Microsoft Corporation” or like.
- productName.autocomplete_startswith – to match stored documents that have tokens that start with tokens in queried text (case insensitive) – Query against “intel corp” will match not just “intel” products, but also “Microsoft Corp“, “Microsoft Corporation“, “Intellisat” etc.
We use combinations of multiple fields in Elasticsearch queries to order search results (most relevant to least relevant). Elasticsearch Bool Query can be used to construct such compound/combinational queries, with different boost values set for sub-queries to get desired result order (default ordering by descending order of _score).
GET product/_search?search_type=dfs_query_then_fetch
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"productName.autocomplete_exact": "intel corp"
}
},
"boost": 300
}
},
{
"constant_score": {
"query": {
"match": {
"productName.autocomplete_phrase": "intel corp"
}
},
"boost": 200
}
},
{
"more_like_this": {
"fields": ["productName.autocomplete_token"],
"like": "intel corp",
"min_term_freq": 1,
"min_doc_freq": 1,
"max_query_terms": 10,
"minimum_should_match": 1,
"boost": 100
}
},
{
"constant_score": {
"query": {
"match": {
"productName.autocomplete_startswith": "intel corp"
}
},
"boost": 10
}
}
],
"minimum_should_match": 1
}
}
}
The above Bool query is composed of Constant Score and More Like This type of queries, which work for us. One should look to replace these sub-queries with appropriate query types, depending on desired search results.
Sometimes, the requirement is to search text in more than one field, with each field stored as multi-fields. For e.g. in our case, user wanted to search in both productName and productDesc fields. In such cases, one could use Dis Max compound query to produce a union of Bool sub-queries (one Bool sub-query per multi-fields field).
GET product/_search?search_type=dfs_query_then_fetch
{
"query": {
"dis_max": {
"queries": [
{
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"productName.autocomplete_exact": "intel corp"
}
},
"boost": 300
}
},
{
"constant_score": {
"query": {
"match": {
"productName.autocomplete_phrase": "intel corp"
}
},
"boost": 200
}
},
{
"more_like_this": {
"fields": ["productName.autocomplete_token"],
"like": "intel corp",
"min_term_freq": 1,
"min_doc_freq": 1,
"max_query_terms": 10,
"minimum_should_match": 1,
"boost": 100
}
},
{
"constant_score": {
"query": {
"match": {
"productName.autocomplete_startswith": "intel corp"
}
},
"boost": 10
}
}
],
"minimum_should_match": 1
}
},
{
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"productDesc.autocomplete_exact": "intel corp"
}
},
"boost": 300
}
},
{
"constant_score": {
"query": {
"match": {
"productDesc.autocomplete_phrase": "intel corp"
}
},
"boost": 200
}
},
{
"more_like_this": {
"fields": ["productDesc.autocomplete_token"],
"like": "intel corp",
"min_term_freq": 1,
"min_doc_freq": 1,
"max_query_terms": 10,
"minimum_should_match": 1,
"boost": 100
}
},
{
"constant_score": {
"query": {
"match": {
"productDesc.autocomplete_startswith": "intel corp"
}
},
"boost": 10
}
}
],
"minimum_should_match": 1
}
}
]
}
}
}
Dis max query generates the union of documents produced by its subqueries, and that scores each document with the maximum score for that document as produced by any subquery, plus a tie breaking increment for any additional matching subqueries.
Here we have discussed just the basic search elements. Elasticsearch provides many other constructs, using which one could filter, rescore (second level of scoring after first search), sort (sort on fields other than on _score) documents, or even use scripting to customize most of these operations. All of these features are quite intuitive to use with Elasticsearch, as we’ve experienced building out our search platform.
Hope you found this article a bit useful. All feedback is welcome.