
Technologies of future (Big Data, IoT, Micro-Services etc.) are optimized to run on commodity hardware and tons of computing, storage and memory resources, which don’t come cheap or fast (“provisioning”). That’s where cloud IaaS and PaaS services come to the rescue. These services enable faster time to market (prototyping anyone?), easy scalability, innovation (AWS Lambda, Azure Cognitive Services etc.) and yes, there’s that cost saving too (if architected and used right though).
But with their advantages, the public cloud technologies have got their share of challenges, due to which their adoption has been slow (particularly in sectors like finance, insurance, auto etc.). In this post, I’ll touch on key general challenges with public cloud technology, and some ways to deal with those if you’re planning to or are already working with Amazon Web Services (AWS) cloud.
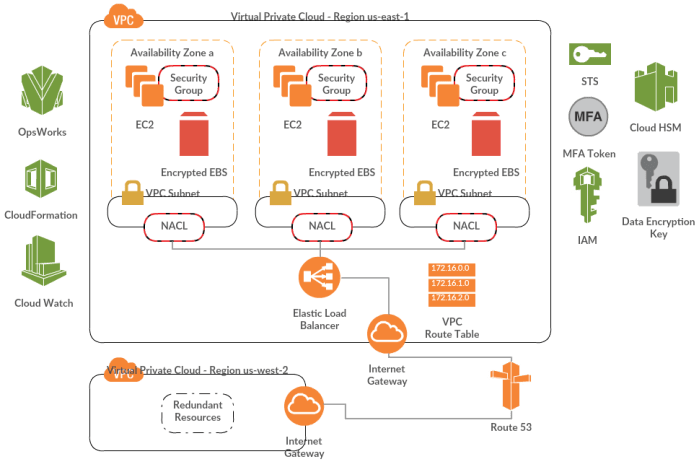
- Security – Yep, that’s the first thing you’ll hear from a skeptical executive about public cloud adoption. And we can’t fault them for that, given the nature of some of their processes and operations. I’ll list a few mechanisms using which an organization can keep their applications secure in AWS cloud:
- Security Groups – In my opinion, this is one of the most basic and powerful features of AWS. It’s just like a private firewall around your instance, which you can configure to control what type of data goes in and out, and to/from specific ports/interfaces. And these are stateful, such that responses to inbound traffic can go out no matter what your outbound traffic restrictions are.
- Access Control Lists (ACLs) – There are network ACLs, which work like Security Groups at the subnet layer. These are also a set of rules, and you can (read should) configure them to allow/deny specific traffic to/from your subnets. These are stateless though, i.e. response traffic must be explicitly configured in allow rules. Then there are S3 ACLs, which you can configure to control access to your S3 buckets and objects. Right combination of Security Groups and ACLs should be utilized when deploying your application(s) to AWS.
- Identity and Access Management (IAM) – IAM is about authentication and authorization for your AWS resources. Whether it’s a developer accessing AWS console from within your firm, or a EC2 instance accessing DynamoDB etc., IAM manages all of it. Think of it as a Directory Service composed of users & groups, and roles assigned to them. You can configure macro to micro level permissions and policies, allowing or denying particular action(s) on particular resource(s). Right policy configurations can protect your applications/resources from unauthorized access. If required, one can also add Multi-factor authentication for account access, enabled via virtual (your phone) or hardware devices (key fob/display card).
- Secure Token Service (STS) – STS provides temporary, limited-privilege credentials for your IAM or federated users (like Active Directory users federated using ADFS). It basically generates a short-lived token (configurable time), using which a user could access required AWS resources during that time. The access is terminated once the token expires. STS is a powerful service which should be used to control access to AWS console or resources.
- Data Privacy – In sensitive environs, like Financial Services, Healthcare, Insurance etc., keeping data secure is a huge deal. And as we’ve seen in recent past, even government services and large internet companies have been victims of data breaches, which leads to loss of trust and clamor for more regulations/laws to protect consumer data. But there’re ways to keep data secure in a public cloud like AWS:
- SSL/TLS for in-transit data – This is basic stuff, but worth reminding. If you have two applications talking to each other, and both are deployed in a private subnet in a VPC, maybe SSL/TLS can be skipped. But in enterprise world, since cloud infrastructure is mostly realized in a hybrid model, you’ll have on-premises applications talking to cloud-deployed applications, and also business users accessing those applications. In such cases, SSL/TLS becomes mandatory.
- Key Management Service (KMS) – KMS is a service to generate and store encryption keys, which can be used to encrypt your data at rest, whether it’s stored in S3, RDS or EBS volumes. The keys can be rotated to ensure that your encryption/decryption process is safe in longer run (just like resetting passwords periodically). KMS also provides an audit trail of key usage.
- Encrypted EBS Volumes – If your data is stored in EBS volumes (self-managed relational database/NoSQL cluster, or a file store etc.), the volumes should be encrypted to keep data secure. The data is encrypted at rest and in transit to/from EC2 instance. A snapshot created from an encrypted volume is also encrypted. Internally, EBS encryption uses KMS managed keys. Encryption is supported for all EBS types, but not all EC2 instance types support encrypted volumes.
- Hardware Security Module (HSM) – This is a tamper-resistant hardware appliance, that can be used to securely store cryptographic key material. Some organizations have to meet strict regulatory and contractual requirements with respect to data security, and HSM devices can aid in such situations. You’ll need a private subnet in your VPC to house the HSM appliance.
- Data Governance – This is a general concept, which should be adopted by organizations looking to move to cloud (if not done yet). Data Governance is not just about creating a fat committee, but it’s identifying different tiers of data, which have different degrees of sensitivity and privacy, and to do that continuously. The exercise helps define guidelines around which data can reside in cloud, and which not. If it’s decided to keep sensitive and confidential data on-premises, a hybrid cloud by way of a VPC (VPN-over-IPSec or Direct Connect) can still be realized to keep your application in cloud, that can access on-premises stored data securely (though the in-transit data should be encrypted).
- Availability – Another area of concern with public clouds has been availability of overall infrastructure and services. Cloud outages were a regular feature in news in the past, leading to downtime for customer applications. Over last couple of years though, major public cloud providers have made considerable improvements to their infrastructure to be able to flaunt availability figures of 99.95% and so. But if you do a rough calculation, even that figure can cause headache for executives. Since cloud service outages are generally location specific, impact to your applications can be avoided through sound architecture decisions:
- Multi-Region Deployment – Regions in AWS are completely isolated geographic areas, providing high level of fault tolerance. For HA (hot-hot or hot-warm) multi-region deployment, one has to consider replication of different resources across regions. EC2 computing instances can be maintained in a hot/warm state, whereas out-of-box cross-region asynchronous replication can be done for data in S3 or RDS. If you manage your own data layer on EC2, you’ll have to implement your own replication mechanism. Network failover can be achieved using Route 53 routing policies (latency based or failover).
- Multi-AZ Deployment – Availability Zones (AZ) in AWS are like isolated data centers within a region. And Amazon has been working to continuously increase number of AZs in major regions. Application and Data clusters should be deployed across different AZs in a region to provide redundancy and load balancing. When employing Multi-Region or Multi-AZ architecture, you mitigate against risk of localized regional failures.
- Utilize DevOps – Automated deployments using configuration management tools/services (AWS OpsWorks, Puppet, Saltstack etc.), along with the power of monitoring triggered actions can help reduce the downtime to a minimum. In addition, DevOps thinking can also help standardize development processes across teams. Thus, it’s imperative to consider DevOps while designing your deployment architecture.
- Vendor lock-in – One other bottleneck regularly mentioned during cloud strategy discussions is locking-in to features and capabilities of a particular cloud provider. People fear that once they are deep into using AWS or Azure or some other public cloud, it’s hard to change down the line. The hesitation is not without reason, because major cloud providers have been so far poor at interoperability. But there’s light at the end of the tunnel. Some organizations are working to create such standards for future, like DMTF Open Virtualization Format (OVF), OASIS TOSCA etc. But until their adoption, there are other options to avoid lock-in. There’re Openstack based cloud providers to choose from, most popular being Rackspace. Or if you have got your eyes set on one of the big guns, you can look at Pivotal Cloud Foundary as a service management platform to abstract a cloud provider. Same can be achieved to a good extent with any configuration management tool as well (listed above in DevOps).
There are other challenges like Compliance with different industry regulations, skill upgrade of existing teams etc. To address the first, public cloud providers like AWS have made long strides in conforming to various standards and regulations to increase wide adoption. For second, problem of stale skills can be managed by investing in brief-to-thorough training programs. And I’m not talking about break-the-bank programs out there, there are much cheaper online options available with good enough content – like cloudacademy.com, linuxacademy.com etc.
Through this post, I just wanted to highlight a few ways on how to tackle key bottlenecks while moving to AWS. These are definitely not end in themselves, nor are these absolutely full-proof solutions. But these can act like a basic checklist, and one should dig deeper to understand nuances and grey areas before adoption.

Thank you very much ! You have cleared out the difference between them.
LikeLike